The Java ByteBuffer – a crash course
Posted: December 14, 2012 Filed under: Uncategorized | Tags: bytebuffer, howto, java, pitfalls, programming, software 11 CommentsIn my experience, java.nio.ByteBuffer is a source of confusion and subtle bugs when developers first encounter it, because it is not immediately obvious how to use it correctly. It took some repeated reading of the API docs and some experience to realize some subtleties, before I felt comfortable with them. This post is a short crash in how to use them correctly, to hopefully save others some trouble.
Since all of this is inferred (rather than based on explicit documentation), and based on experience, I cannot claim the information is necessarily authoritative. I welcome feedback to point out mistakes or alternative points of view. I also welcome suggestions for additional pitfalls/best practices to cover.
I do assume that the reader will be looking at the API documentation to go with this post. I am not going to be exhaustive on all the possible things you can dowith a ByteBuffer.
The ByteBuffer abstraction
Look at a ByteBuffer as providing a view into some (undefined) underlying storage of bytes. The two most common concrete types of byte buffers are those backed by byte arrays, and those backed by direct (off-heap, native) byte buffers. In both cases, the same interface can be used to read and write contents of the buffer.
Some parts of the API of a ByteBuffer is specific to some types of byte buffers. For example, a byte buffer can be read-only, restricting usage to a subset of methods. The array() method will only work for a byte buffer backed by a byte array (which can be tested with hasArray()) and should generally only be used if you know exactly what you are doing. A common mistake is to use array() to “convert” a ByteBuffer into a byte array. Not only does this only work for byte array backed buffers, but it is easily a source of bugs because depending on how the buffer was created, the beginning of the returned array may or may not correspond to the beginning of the ByteBuffer. The result tends to be a subtle bug where the behavior of code differs depending on implementation details of the byte buffer and the code that created it.
A ByteBuffer offers the ability to duplicate itself by calling duplicate(). This does not actually copy the underlying bytes, it only creates a new ByteBuffer instance pointing to the same underlying storage. A ByteBuffer representing a subset of another ByteBuffer may be created using slice().
Key differences from byte arrays
- A ByteBuffer has value semantics with respect to hashCode()/equals() and as a result can be more conveniently used in containers.
- A ByteBuffer has offers the ability to pass around a subset of a byte buffer as a value without copying the bytes, by instantiating a new ByteBuffer.
- The NIO API makes extensive use of ByteBuffer:s.
- The bytes in a ByteBuffer may potentially reside outside of the Java heap.
- A ByteBuffer has state beyond the bytes themselves, which facilitate relative I/O operations (but with caveats, talked about below).
- A ByteBuffer offers methods for reading and writing various primitive types like integers and longs (and can do it in different byte orders).
Key properties of a ByteBuffer
The following three properties of a ByteBuffer are critical (I’m quoting the API documentation on each):
- A buffer’s capacity is the number of elements it contains. The capacity of a buffer is never negative and never changes.
- A buffer’s limit is the index of the first element that should not be read or written. A buffer’s limit is never negative and is never greater than its capacity.
- A buffer’s position is the index of the next element to be read or written. A buffer’s position is never negative and is never greater than its limit.
Here is a visualization of an example ByteBuffer which is (in this case) backed by a byte array, and the value of the ByteBuffer is the word “test” (click it to zoom):
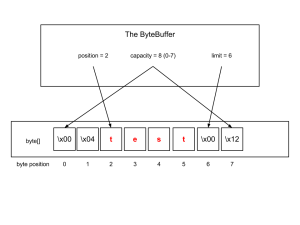
That ByteBuffer would be equal to (in the sense of equals()) to any other ByteBuffer whose contents in between [position,limit) is the same.
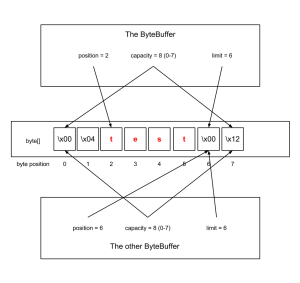
Suppose the byte buffer visualized above was bb, and we did this:
final ByteBuffer other = bb.duplicate(); other.position(bb.position() + 4);
We would now have two ByteBuffer instances both referring to the same underlying byte array, but their contents would be different (other would be empty):
The buffer/stream duality of byte buffers
There are two ways of accessing the contents of a byte buffer – absolute and relative access. For example, suppose I have a ByteBuffer that I know contains two integers. In order to extract the integers using absolute positioning, one might do this:
int first = bb.getInt(0) int second = bb.getInt(4)
Alternatively one can extract them using relative positioning:
int first = bb.getInt(); int second = bb.getInt();
The second option is often convenient, but at the cost of having a side-effect on the buffer (i.e., changing it). Not the contents itself, but the ByteBuffers view into that content.
In this way, ByteBuffers can behave similarly to a stream, if used as such.
Best practices and pitfalls
flip() the buffer
If you are building up a ByteBuffer by repeatedly writing into it, and then want to give it away, you must remember to flip() it. For example, here is a method that copies a byte array into a ByteBuffer, assuming default encoding (note that ByteBuffer.wrap(), which is used here, creates a ByteBuffer that wraps the specified byte array, as opposed to copy the contents of it into a new ByteBuffer):
public static ByteBuffer fromByteArray(byte[] bytes) {
final ByteBuffer ret = ByteBuffer.wrap(new byte[bytes.length]);
ret.put(bytes);
ret.flip();
return ret;
}
If we did not flip() it, the returned ByteBuffer would be empty because the position would be equal to the limit.
Don’t consume the buffer
Be careful not to “consume” a byte buffer when reading it, unless you specifically intend on doing so. For example, consider this method to convert a ByteBuffer into a String, assuming default encoding:
public static String toString(ByteBuffer bb) {
final byte[] bytes = new byte[bb.remaining()];
bb.duplicate().get(bytes);
return new String(bytes);
}
Unfortunately, there is no method provided to do absolute positioning reads of a byte array (but there does exist absolute positioning reads for the primitives).
Notice the use of duplicate() when reading the bytes. If we did not, the function would have a side-effect on the input ByteBuffer. The cost of doing this is the extra allocation of a new ByteBuffer just for the purpose of the one call to get(). You could record the position of the ByteBuffer prior to the get() and restore it afterwards, but that has thread-safety issues (see next section).
It is worth noting that this only applies when you are trying to treat ByteBuffer:s as values. If you are writing code whose purpose is do side-effect on ByteBuffers, treating them more like streams, you would of course be intending to do so and this section does not apply.
Don’t mutate the buffer
In the context of general-purpose code which is not intimately specific to a particular use-case, it is (in my opinion) good practice for a method that does an (abstractly) read-only operation (such as reading a byte buffer), to not mutate its input. This is a stronger requirement than “Don’t consume the ByteByffer”. Take the example from the previous section, but with an attempt to avoid the extra allocation of the ByteBuffer:
public static String toString(ByteBuffer bb) {
final byte[] bytes = new byte[bb.remaining()];
bb.mark(); // NOT RECOMMENDED, don't do this
bb.get(bytes);
bb.reset(); // NOT RECOMMENDED, don't do this
return new String(bytes);
}
In this case, we record the state of the ByteBuffer prior to our call to get() and restore it afterwards (see the API documentation for mark() and reset()). There are two problems with this approach. The first problem is that the function above does not compose. A ByteBuffer only has one “mark”, and your (very general, not context aware) toString() method cannot safely assume that the caller is not trying to use mark() and reset() for its own purposes. For example, imagine this caller which is de-serializing a length-prefixed string:
bb.mark(); int length = bb.getInt(); ... sanity check length final String str = ByteBufferUtils.toString(bb); ... do something bb.reset(); // OOPS - reset() will now point 4 bytes off, because toString() modified the mark
(As an aside, this is a very contrived and strange example, because I found it hard to come up with a realistic example of code that uses mark()/reset(), which is typically used when treating the buffer in a stream-like faction, which would also feel the need to call toString() on the remainder of said buffer. I’d be interested in hearing what solutions people have come up with here. For example, one could imagine clear policies in a code base that allow mark()/reset() in value oriented contexts like toString() – but even if you did (and it smells likely to be inadvertently violated) you would still suffer the mutation problem mentioned later.)
Let’s look at an alternative version of toString() that avoids this problem:
public static String toString(ByteBuffer bb) {
final byte[] bytes = new byte[bb.remaining()];
bb.get(bytes);
bb.position(bb.position() - bytes.length); // NOT RECOMMENDED, don't do this
return new String(bytes);
}
In this case we are not modifying the mark, so we do compose. However, we are still committing the “crime” of mutating our input. This is a problem in multi-threaded situations; you don’t want reading something to imply mutating it, unless the abstraction implies it (for example, with a stream or when using ByteBuffers in a stream-like fashion). If you’re passing around a ByteBuffer treating it as a value, putting it in containers, sharing them, etc – mutating them will introduces subtle bugs unless you are guaranteed that two threads never ever use the same ByteBuffer at the same time. Typically, the result of this type of bug is strange corruption of values or unexpected BufferOverFlowException:s.
A version that suffers from neither of this appears in the “Don’t consume the buffer” section above, which uses duplicate() to construct a temporary ByteBuffer instance on which it is safe to call get().
compareTo() is subject to byte signedness
bytes in Java are signed, contrary to what one typically expects. What is easy to miss though, is the fact that this affects ByteBuffer.compareTo() as well. The Java API documentation for that method reads:
“Two byte buffers are compared by comparing their sequences of remaining elements lexicographically, without regard to the starting position of each sequence within its corresponding buffer.”
A quick reading might lead one to believe the result is what you would typically expect, but of course given the definition of a byte in Java, this is not the case. The result is that the order of byte buffers that contains values with the highest order bit set, will diverge from what you may be expecting.
Google’s excellent Guava library has an UnsignedBytes helper to mitigate your pain.
array() is usually the wrong method to use
Generally, don’t use array() casually. In order for it to be used correctly you either have to know for a fact that the byte buffer is array backed, or you have to test it with hasArray() and have two separate code paths for either case. Additionally, when you use it, you must use arrayOffset() in order to determine what the zeroth position of the ByteBuffer corresponds to in the byte array.
In typical application code, you would not use array() unless you really know what you are doing and you specifically need it. That said, there are cases where it’s useful. For example, supposing you were implementing a ByteBuffer version of UnsignedBytes.compare() (again, from Guava) – you may wish to optimize the case where either or both of the arguments are array backed, to avoid unnecessary copying and frequent calls to the buffers. For such a generic and potentially heavily used method, such an optimization would make sense.
